stt - docker wyoming-vosk
A standalone container for vosk using the wyoming protocol. come from hass.io addon.
Table of Contents
https://github.com/users/mslycn/packages/container/package/wyoming-vosk-standalone
docker pull ghcr.io/mslycn/wyoming-vosk-standalone:1.5.0Note:only for amd64
As for docker, it doesn't work on ARM. Instead, you can install vosk with pip and clone and run the server.
output
vosk_1 | DEBUG:root:Transcript for client 869914473928554: 开灯
vosk_1 | DEBUG:root:Client disconnected: 869914473928554
vosk_1 | DEBUG:root:Client connected: 870084270467609
vosk_1 | DEBUG:root:Loaded recognizer in 0.21 second(s)
vosk_1 | DEBUG:root:Transcript for client 870084270467609: 开灯
vosk_1 | DEBUG:root:Client disconnected: 870084270467609
github:https://github.com/dekiesel/wyoming-vosk-standalone
How it works
This is the code!
Download a Vosk model
from vosk import Model, KaldiRecognizer
import wave
import time
# Start timer
start_time = time.perf_counter()
wf = wave.open("audio-en.wav", "rb")
model = Model("models/vosk-model-small-en-us-0.15") # Download a Vosk model and specify the path
rec = KaldiRecognizer(model, wf.getframerate())
while True:
data = wf.readframes(4000)
if len(data) == 0:
break
if rec.AcceptWaveform(data):
print(rec.Result())
# End timer
end_time = time.perf_counter()
# Calculate elapsed time
elapsed_time = end_time - start_time
print(f"Elapsed time: {elapsed_time:.6f} seconds")performs Speech to Text
import pyaudio
import wave
from vosk import Model, KaldiRecognizer
import time
import numpy as np
import collections
# Constants
DEVICE_INDEX = 1 # Update this to match your headset's device index
RATE = 16000 # Sample rate
CHUNK = 1024 # Frame size
FORMAT = pyaudio.paInt16
RECORD_SECONDS = 10 # Duration to record after detecting voice
THRESHOLD = 500 # Adjust this to match your environment's noise level
MODEL_PATH = "models/vosk-model-small-tr-0.3" # Path to your Vosk model
OUTPUT_FILE = "translate.wav"
# Initialize PyAudio
audio = pyaudio.PyAudio()
# Open stream
stream = audio.open(
format=FORMAT,
channels=1,
rate=RATE,
input=True,
input_device_index=DEVICE_INDEX,
frames_per_buffer=CHUNK
)
print("Listening for voice...")
def detect_voice(audio_chunk):
"""Return True if audio chunk likely contains a human voice."""
# Decode byte data to int16
try:
audio_chunk = np.frombuffer(audio_chunk, dtype=np.int16)
except ValueError as e:
print(f"Error decoding audio chunk: {e}")
return False
# Inspect the range of audio data
print(f"Min: {audio_chunk.min()}, Max: {audio_chunk.max()}")
# Compute the volume
volume = np.abs(audio_chunk).max() # Use absolute to handle both +ve and -ve peaks
print(f"Volume: {volume}")
# Define threshold (adjust based on testing)
THRESHOLD = 1000 # Adjust based on normalized scale
return volume > THRESHOLD
# Parameters for silence detection
SILENCE_TIMEOUT = 2 # seconds of silence to stop recording
MAX_SILENCE_CHUNKS = int(SILENCE_TIMEOUT * RATE / CHUNK) # Convert to chunk count
# Record audio with silence detection
frames = []
silent_chunks = 0
# Wait for voice
# Add a buffer to store audio chunks before voice is detected
pre_record_buffer = collections.deque(maxlen=int(RATE / CHUNK * 2)) # Buffer up to 2 seconds of audio
print("Listening for voice...")
while True:
data = stream.read(CHUNK, exception_on_overflow=False)
pre_record_buffer.append(data) # Continuously store audio chunks
if detect_voice(data):
print("Voice detected! Starting recording...")
frames.extend(pre_record_buffer) # Include pre-recorded audio
frames.append(data) # Include the current chunk with voice
break
print("Recording... Speak now.")
while True:
data = stream.read(CHUNK, exception_on_overflow=False)
frames.append(data)
# Detect silence
if not detect_voice(data):
silent_chunks += 1
if silent_chunks >= MAX_SILENCE_CHUNKS:
print("Silence detected. Stopping recording...")
break
else:
silent_chunks = 0 # Reset silence counter if voice is detected
# Stop and close stream
stream.stop_stream()
stream.close()
audio.terminate()
# The 'frames' list now contains the recorded audio data.
# Save audio to file
with wave.open(OUTPUT_FILE, "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(audio.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b"".join(frames))
print(f"Audio recorded to {OUTPUT_FILE}")
# Start speech-to-text
print("Starting speech-to-text...")
start_time = time.perf_counter()
wf = wave.open(OUTPUT_FILE, "rb")
model = Model(MODEL_PATH)
rec = KaldiRecognizer(model, wf.getframerate())
while True:
data = wf.readframes(4000)
if len(data) == 0:
break
if rec.AcceptWaveform(data):
print("Transcription:", rec.Result())
# End timer
end_time = time.perf_counter()
elapsed_time = end_time - start_time
print(f"Elapsed time: {elapsed_time:.6f} seconds")
How to use
clone the repo
change into the repo: cd wyoming-vosk-standalone
build the container: bash build.sh
optional: adapt docker-compose.yaml to your use-case
run the container: docker compose up
A directory called dirs will be created in the current folder. Inside that folder are the volumes specified in docker-compose.yaml
VOSK Models
https://alphacephei.com/vosk/models
Step 1.Build docker wyoming-vosk image
# clone the repo
git clone https://github.com/dekiesel/wyoming-vosk-standalone
# change into the repo
cd wyoming-vosk-standalone
# list files
ls -l
total 20
-rw-r--r-- 1 root root 286 Feb 11 13:07 build.sh
-rw-r--r-- 1 root root 427 Feb 11 13:07 docker-compose.yaml
-rw-r--r-- 1 root root 826 Feb 11 13:07 Dockerfile
-rw-r--r-- 1 root root 1366 Feb 11 13:07 README.md
-rw-r--r-- 1 root root 1230 Feb 11 13:07 start.sh
# build the container
bash build.sh
output
# cd wyoming-vosk-standalone
root@debian:~/wyoming-vosk-standalone# bash build.sh
[+] Building 965.1s (9/9) FINISHED docker:default
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 865B 0.0s
=> [internal] load metadata for ghcr.io/home-assistant/amd64-base-debian:bookworm 3.2s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/5] FROM ghcr.io/home-assistant/amd64-base-debian:bookworm@sha256:1ce7ca169e5c8b77300ceacb592c656467945 57.4s
=> => resolve ghcr.io/home-assistant/amd64-base-debian:bookworm@sha256:1ce7ca169e5c8b77300ceacb592c6564679457 0.0s
=> => sha256:e8a35b731771e17379eb8c5c148a1f808758a1d5751e02b6ad05e4ee27f7e427 4.70kB / 4.70kB 0.0s
=> => sha256:8cf9fb7a0b56cf93bf2502aff8087344f2dd06e29fb027b0c06aa2726ab3eda8 29.15MB / 29.15MB 54.9s
=> => sha256:4f4fb700ef54461cfa02571ae0db9a0dc1e0cdb5577484a6d75e68dc38e8acc1 32B / 32B 3.0s
=> => sha256:40f89111e0f7ff5e130192aa23a37ddc22939ec3953b7a8c959431de22c8fee9 10.69MB / 10.69MB 42.5s
=> => sha256:1ce7ca169e5c8b77300ceacb592c6564679457cf02ab93f9c2a862b564bb6d94 947B / 947B 0.0s
=> => extracting sha256:8cf9fb7a0b56cf93bf2502aff8087344f2dd06e29fb027b0c06aa2726ab3eda8 1.8s
=> => extracting sha256:4f4fb700ef54461cfa02571ae0db9a0dc1e0cdb5577484a6d75e68dc38e8acc1 0.0s
=> => extracting sha256:40f89111e0f7ff5e130192aa23a37ddc22939ec3953b7a8c959431de22c8fee9 0.4s
=> [internal] load build context 0.0s
=> => transferring context: 1.27kB 0.0s
=> [2/5] WORKDIR /usr/src 3.0s
=> [3/5] RUN apt-get update && apt-get install -y --no-install-recommends netcat-traditiona 900.1s
=> [4/5] COPY start.sh /start.sh 0.0s
=> exporting to image 1.3s
=> => exporting layers 1.3s
=> => writing image sha256:00fe184759813d092368d6e006935d5c2f5ef67283660889d3cef886ad7b3100 0.0s
=> => naming to docker.io/library/wyoming-vosk-standalone:1.5.0
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
wyoming-vosk-standalone 1.5.0 00fe18475981 23 minutes ago 220MB
movedwhisper latest 9455da0dfada 2 weeks ago 564MB
Step 2.Run first
en
version: "2"
services:
vosk:
image: wyoming-vosk-standalone:1.5.0
environment:
- CORRECT_SENTENCES=0.0
- PRELOAD_LANGUAGE=en
- DEBUG_LOGGING=TRUE
- LIMIT_SENTENCES=TRUE
- ALLOW_UNKNOWN=False
volumes:
- ./dirs/data:/data
- ./dirs/sentences:/share/vosk/sentences
- ./dirs/models:/share/vosk/models
ports:
- 10300:10300
restart: unless-stopped
cn
version: "2"
services:
vosk:
image: ghcr.io/mslycn/wyoming-vosk-standalone:1.5.0
environment:
- CORRECT_SENTENCES=0.0
- PRELOAD_LANGUAGE=cn
- DEBUG_LOGGING=TRUE
- LIMIT_SENTENCES=TRUE
- ALLOW_UNKNOWN=False
volumes:
- ./dirs/data:/data
- ./dirs/sentences:/share/vosk/sentences
- ./dirs/models:/share/vosk/models
ports:
- 10300:10300
restart: unless-stopped
Run first
cd /vosk/cd wyoming-vosk-standalone
docker-compose up
output
WARN[0000] /root/wyoming-vosk-standalone/docker-compose.yaml: the attribute `version` is obsolete, it will be ignored, please remove it to avoid potential confusion
Attaching to vosk-1
vosk-1 | CORRECT_SENTENCES = 0.0
vosk-1 | PRELOAD_LANGUAGE = en
vosk-1 | DEBUG_LOGGING = TRUE
vosk-1 | LIMIT_SENTENCES = TRUE
vosk-1 | ALLOW_UNKNOWN = False
vosk-1 | flags = --debug --limit-sentences
vosk-1 | DEBUG:root:Namespace(uri='tcp://0.0.0.0:10300', data_dir=['/share/vosk/models'], download_dir='/data', language='en', preload_language=['en'], model_for_language={}, casing_for_language={}, model_index=0, sentences_dir='/share/vosk/sentences', database_dir='/share/vosk/sentences', correct_sentences=0.0, limit_sentences=True, allow_unknown=False, debug=True, log_format='%(levelname)s:%(name)s:%(message)s')
vosk-1 | DEBUG:root:Preloading model for en
vosk-1 | DEBUG:wyoming_vosk.download:Downloading: https://huggingface.co/rhasspy/vosk-models/resolve/main/en/vosk-model-small-en-us-0.15.zip
A directory called dirs will be created in the current folder.
~/wyoming-vosk-standalone# ls -l
total 24
-rw-r--r-- 1 root root 286 Feb 11 13:07 build.sh
drwxr-xr-x 5 root root 4096 Feb 11 13:58 dirs
-rw-r--r-- 1 root root 427 Feb 11 13:07 docker-compose.yaml
-rw-r--r-- 1 root root 826 Feb 11 13:07 Dockerfile
-rw-r--r-- 1 root root 1366 Feb 11 13:07 README.md
-rw-r--r-- 1 root root 1230 Feb 11 13:07 start.sh
output
LOG (VoskAPI:ReadDataFiles():model.cc:282) Loading HCL and G from /share/vosk/models/vosk-model-small-de-0.15/graph/HCLr.fst /share/vosk/models/vosk-model-small-de-0.15/graph/Gr.fst
LOG (VoskAPI:ReadDataFiles():model.cc:308) Loading winfo /share/vosk/models/vosk-model-small-de-0.15/graph/phones/word_boundary.int
INFO:root:Ready
other
apt install docker-compose
https://docs.docker.com/compose/install/standalone/
Step 3.Using a specific model
Models are automatically downloaded from HuggingFace, but they are originally from Alpha Cephei(https://alphacephei.com/vosk/models).
vosk-model-small-cn-0.22 42M
vosk-model-cn-0.22 1.3G
# cd into the models directory
cd dirs/models
# Download the model
wget https://alphacephei.com/vosk/models/vosk-model-small-cn-0.22.zip
wget https://alphacephei.com/vosk/models/vosk-model-cn-0.22.zip
wget https://alphacephei.com/vosk/models/vosk-model-cn-kaldi-multicn-0.15.zip
# ls -l
total 1913544
-rw-r--r-- 1 root root 1358736686 Jun 1 2022 vosk-model-cn-0.22.zip
-rw-r--r-- 1 root root 556773376 Feb 11 14:11 vosk-model-cn-kaldi-multicn-0.15.zip
-rw-r--r-- 1 root root 43898754 May 1 2022 vosk-model-small-cn-0.22.zip
# unzip
unzip vosk-model-small-cn-0.22.zip
unzip vosk-model-cn-0.22.zip
unzip vosk-model-cn-kaldi-multicn-0.15.zip
# vosk uses the foldername to determine the language
mv vosk-model-small-cn-0.22 cn
mv vosk-model-cn-0.22 cn
mv vosk-model-cn-kaldi-multicn-0.15 cn
Step 5.connect vosk to HA via wyoming integration
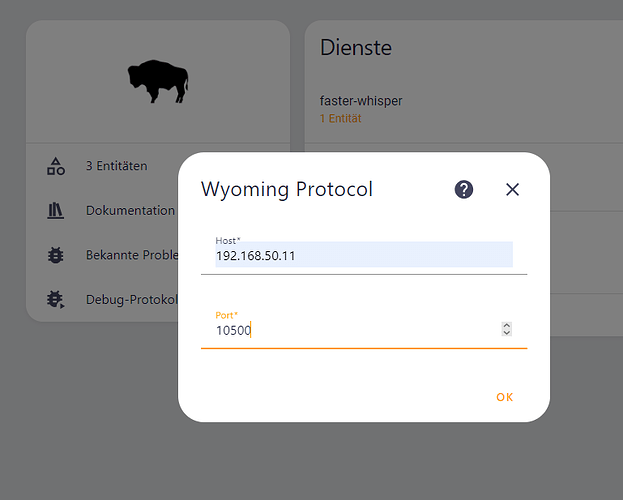
Accuracy
Recognition is very poor compared to Whisper with small model.
Thanks to https://github.com/alphacep/vosk-api team.
Solution: Running docker images on arm64
https://github.com/alphacep/vosk-server/issues/209
Comments
Comments are closed